- The Deep View
- Posts
- LLMs won't get us to AGI: Sustkever
LLMs won't get us to AGI: Sustkever
The Deep View
December 02, 2025


Welcome back. Just as new reports strongly suggested that OpenAI was about to roll out advertising on ChatGPT to accelerate the company's revenue growth, Sam Altman tapped the brakes on ads and other initiatives. According to The Information, the OpenAI CEO declared a "code red" to his staff on Monday. He rallied the team around one idea: improving ChatGPT to meet the challenges posed by competitors. It's the latest development in a surprising turnaround in the AI space. In August, OpenAI released its latest flagship model, GPT-5, which failed to deliver the same level of advances as previous models. This happened in the shadow of OpenAI losing its two most prominent technical leaders, Ilya Sutskever and Mira Murati, during the past year. But the biggest blow came in November when Google released its new flagship model, Gemini 3, which delivered the kinds of big leaps forward that we were used to seeing from OpenAI.
1. LLMs won't get us to AGI: Sustkever
2. DeepSeek's new models rival OpenAI, Google
3. US data centers to double over next 10 years
BIG TECH
LLMs won't get us to AGI: Sustkever

Generative AI might need to grow out, not up.
Frontier model firms continue to scale their LLMs to new heights in the pursuit of artificial general intelligence that can do it all. But another one of the field’s leading scholars is questioning whether bigger is actually better.
On a podcast with Dwarkesh Patel last week, Ilya Sustkever, OpenAI co-founder and founder of Safe Superintelligence, called into question the validity of scaling laws, or the idea that developing larger and more powerful models inherently makes them better. Sutskever noted that in 2020, we moved from the “age of research” to the “age of scaling,” with the goal shifting from discovering new AI models to pure growth.
Though the bigger equals better mentality is a “very low-risk way” of investing resources, Sustkever said, some are starting to realize that scale isn’t everything. “It’s back to the age of research again, just with big computers,” he told Patel.
Sustkever isn’t the only one challenging the current frenzy around scaling large language models.
Yann Lecun, Meta AI’s former chief scientist and one of the so-called godfathers of AI, said on the Big Technology podcast in May that large language models won’t be the way we achieve “human-level AI.”
Benjamin Riley, founder of Cognitive Resonance, wrote in an essay published in The Verge last week that human thinking and language are two distinct things. “We use language to think, but that does not make language the same as thought,” Riley wrote.
The increased skepticism is coinciding with a growing interest in AI that better understands the world around us. In November, Dr. Fei-Fei Li’s World Labs released Marble, its first commercial world model project focused on “spatial intelligence.” Researchers at Mohamed bin Zayed University of Artificial Intelligence released their next-generation world model, PAN, last month. And robotics firm Physical Intelligence last week raised $600 million, valuing the startup at $5.6 billion.
The recent hype around robotics and world models signals that researchers and investors alike are looking beyond language models for the next advances in AI.
Though industry leaders are butting heads on the path to AI that can do it all, the question remains: If we ever achieve AGI, what is the point of it? How can enterprises, governments, or individuals leverage a model that can do it all? What is the purpose of that kind of power? Research has shown that small models have made incredible strides at handling niche tasks within enterprises, and may even outperform large models at certain tasks. Plus, small models tend to be more affordable and less resource-intensive. The world's current massive data center buildout is based on the premise that scaling laws will remain universally true for years to come. Now that scaling is being called into question, it raises serious questions about whether it's worth the trillion-dollar price tag.
TOGETHER WITH OUTSKILL

It’s 2026 and if you still have not really invested time in learning AI, this is your last, golden chance.🥇
It will not just make you skilled, but a money making machine and get richer & smarter as you step into 2026. 🚀 I am already in!
Introducing a 2-Day LIVE AI Mastermind by Outskill – an intensive training on AI tools, automations, and agent building that'll make you indispensable.
Best part? They’re running their Holiday Season Giveaway and first 100 people get in for absolutely free (it usually costs $395 to attend 🫨)
🧠Live sessions- Saturday and Sunday
🕜10 AM EST to 7PM EST
🎁 You will also unlock $5000+ in AI resources: (as bonuses when you show up!)
A Prompt Bible 📚,
Roadmap to Monetize with AI 💰
Personalised AI toolkit builder ⚙️
Register here for $0 (first 100 people only) 🎁
PRODUCTS
DeepSeek's new models rival OpenAI, Google

Chinese AI company DeepSeek unveiled two new models that it says perform comparably to top offerings from OpenAI and Google.
The first of the new models, DeepSeek-V3.2, outperformed OpenAI’s GPT-5 on several benchmarks, according to a paper published by DeepSeek. Its second new model, DeepSeek-V3.2-Speciale, performs comparably to Google’s Gemini 3.0, DeepSeek said. DeepSeek’s newest models continue the firm’s modus operandi for efficiency. The new models can process the equivalent of a 300-page book at 70% less inference cost than DeepSeek’s previous model, according to VentureBeat.
This efficiency is enabled by DeepSeek Sparse Attention (DSA), a new piece of infrastructure that scales attention mechanisms (the means by which AI understands context). Unlike traditional attention mechanisms, which can exponentially increase computational complexity as sequence length increases, DSA uses only the most relevant context, leading to significant gains in computational efficiency. V3.2-Speciale does lag behind Gemini 3.0 in token efficiency, DeepSeek noted.

DeepSeek model performance and token usage compared to other popular models.
Source: DeepSeek
DeepSeek made waves across the tech world when it debuted its R1 reasoning model in January 2025. The model performed similarly to ChatGPT but was trained on inferior hardware and at a fraction of the cost. The release seemingly challenged conventional wisdom that growing demand for AI would create ever-higher demand for advanced chips, leading Nvidia to shed a record $589 billion in market capitalization in a single day. (The stock has since recovered.)
Adding to the intrigue, DeepSeek has released its models under the open-source MIT license, in contrast to AI giants like OpenAI and Google, whose models live in proprietary black boxes. With the new release, DeepSeek has once again proven its ability to produce models on par with its US competitors — despite US regulatory efforts to thwart Chinese AI advancement.
When DeepSeek unveiled its R1 model in January, a16z boss Marc Andreesen called it “AI’s Sputnik moment.” These impressive new models from DeepSeek only further the notion that, despite its first-mover advantage and access to cutting-edge chips, the US may have real AI competition in China. The high quality achieved by DeepSeek’s computationally efficient, open-source models may also further a noteworthy recent trend — US-based AI firms opting to build on Chinese models, which can be cheaper and of comparable quality to their American counterparts.
TOGETHER WITH VANTA
State of Trust: Knowledge Gaps = Security Gaps

AI is moving faster than security teams can keep up—59% say AI risks outpace their expertise.
This is according to Vanta’s new State of Trust report, which surveyed 3,500 business and IT leaders across the globe.
Download the report to learn how organizations are navigating this gap, and what early adopters are doing to stay ahead.
HARDWARE
US data centers to double over next 10 years

Power demand from data centers is projected to hit 106 gigawatts by 2035, according to a new report from BloombergNEF, a 36% increase from its previous estimate. Data centers use roughly 40 gigawatts today.
The AI industry’s massive growth has driven up demand for data centers that provide the computing power needed to run the software. The growing power demand from data centers is likely to create an “inflection point for US grids,” BloombergNEF said.
Big Tech continues to shell out seemingly unlimited CapEx on AI, and a sizable chunk of that spending is going toward the data centers to scale it and meet growing demand. Microsoft spent $11.1 billion on data center leases last quarter, accounting for 31% of its overall spending.
Interestingly, BloombergNEF’s data center demand estimate may be somewhat conservative. Deloitte estimates data center demand would hit 176 GW by 2035, and Goldman Sachs projects data center demand to reach 92 GW by 2027 — a far higher growth rate than in BloombergNEF’s projection.
Growing demand is shifting the geography of data centers. As northern Virginia — historically the dominant region for data centers — becomes saturated, new projects are cropping up in southern and central Virginia, and data center projects in Georgia are moving further from Atlanta, the report notes. In Texas, former bitcoin mining sites are being repurposed for AI.
Energy grid capacity qualms aside, this report looks bullish for AI. The AI industry needs to grow rapidly to justify the accelerating capex and frothy valuations of AI companies. If data center demand truly does grow as quickly as BloombergNEF estimates, perhaps AI can keep the bubble from bursting. But if smaller models become more prevalent and more efficient models like the new ones from DeepSeek disrupt the industry, it could undermine the need for data centers and result in a glut of capacity — something that seems unimaginable in the current environment.
LINKS

Nvidia takes $2 billion stake in Synopsys to expand compute power
OpenAI takes stake in Thrive Capital to embed AI in holding companies
Databricks raises $5 billion at $134 billion valuation
AI agents on AWS marketplace hits 2,100 — 40 times higher than expected
Apple AI head John Giannandrea is stepping down after Siri delays
Colleges and universities lean into AI major programs

Whisper Thunder: Gen-4.5, a new video generation model from Runway that beats OpenAI and Google in key benchmarks.
TwelveLabs Marengo 3.0: New foundation model from TwelveLabs for semantic video understanding.
Nvidia Alpamayo-R1: Nvidia’s latest open reasoning vision language model for AI driving research
NeuralAgent: An AI teammate that isn’t stuck in a sandbox, actually controlling your PC



A QUICK POLL BEFORE YOU GO
Can LLMs scale all the way to AGI? |
The Deep View is written by Nat Rubio-Licht, Jack Kubinec, Jason Hiner, Faris Kojok and The Deep View crew. Please reply with any feedback.
Thanks for reading today’s edition of The Deep View! We’ll see you tomorrow.
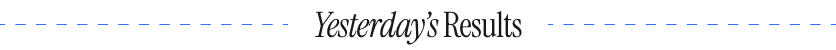
“No snow under the car. It looks as it should.” “License plate was the tell.” “The unusual pattern on the windows and the perfect lighting of [the other image] suggest fake to me.” |

“Having grown up in MN, I can’t imagine why anyone in real life would wipe snow off the passenger window.” “The snow texture seemed deficient in the real image likely due to poorer quality” “The precision of the snow on the front grill just doesn’t look right to me.“ |

Take The Deep View with you on the go! We’ve got exclusive, in-depth interviews for you on The Deep View: Conversations podcast every Tuesday morning.
If you want to get in front of an audience of 450,000+ developers, business leaders and tech enthusiasts, get in touch with us here.